Introduction
In today's data-driven landscape, the power of analytical insights is maximized when they are put into action. Databricks Delta Lake provides a robust platform for large-scale analytics and AI. However, these insights often need to be delivered to operational systems, AI agents, and customer-facing applications to drive immediate business value. This is where Reverse ETL comes into play.
Reverse ETL is the process of moving data from a central data warehouse or data lake (like Databricks Delta Lake) back into operational systems.
This guide provides a comprehensive walkthrough on implementing Reverse ETL pipelines to synchronize data from your Databricks Delta Lake into a Neon Postgres database. We'll cover the strategic "why," architectural considerations, a detailed technical implementation with PySpark, best practices, and how this pattern fits into the evolving Databricks ecosystem.
Why Reverse ETL from Databricks Delta Lake to Neon Postgres?

The primary goal is to bridge the gap between powerful analytics performed in Databricks and the operational systems that drive daily business processes. Databricks excels at processing and analyzing vast datasets, while Neon provides a highly performant, serverless Postgres experience ideal for operational workloads.
Key Benefits
- Activate Data for applications: Make refined data (e.g., customer segments, product recommendations, inventory levels) directly available to web/mobile apps, CRMs, marketing tools, and other operational systems for immediate use.
- Enhance customer experiences: Deliver personalized content, targeted offers, and timely support by feeding real-time customer insights from Delta Lake into Neon-backed applications.
- Empower AI and Automation: Provide AI agents and automated workflows with fresh, curated data from Delta Lake via Neon to improve decision-making and task execution.
- Improve operational efficiency: Streamline business processes by ensuring operational tools have access to the latest, analytics-driven information, reducing manual work and latency.
Common use cases:
- Populating user profiles in a customer-facing application with data from Delta Lake.
- Syncing product recommendations or eligibility scores to an e-commerce platform.
- Updating inventory or pricing in real-time for operational dashboards and systems.
- Feeding personalized data to marketing automation tools or customer support platforms.
Using Third-party Reverse ETL tools
While this guide focuses on a hands-on approach using Databricks notebooks and Spark, it's worth noting that several third-party Reverse ETL platforms can automate and manage these data synchronization pipelines. Tools like Hightouch, Census, Rivery, Fivetran, and RudderStack offer pre-built connectors and a managed service to move data from data warehouses like Databricks to operational systems, including Postgres databases like Neon. These platforms can simplify setup and maintenance, especially for teams looking for a less code-intensive solution.
However, if you prefer a custom-built pipeline with full control over the process, this guide will walk you through the detailed steps using only your Databricks environment.
Architectural considerations for Reverse ETL
The typical Reverse ETL flow involves extracting transformed data from Delta Lake, processing it if necessary, and loading it into Neon Postgres.
Key synchronization patterns
- Initial Load (Full Batch Sync): For the first-time setup, a full load of historical data from the Delta table to the target Neon table is often required.
- Incremental syncs (Ongoing):
- Batch CDC: Using Delta Lake's Change Data Feed (CDF), process changes in batches on a defined schedule (e.g., every 5 minutes, hourly). This is efficient as only changed data is moved.
- Streaming CDC: For lower latency, leverage Spark Structured Streaming with Delta Lake CDF as a source to continuously process and sync changes to Neon in near real-time.
Bridging analytical and operational paradigms
Databricks Delta Lake is designed for large-scale analytical processing, while Neon Postgres is an OLTP database optimized for transactional workloads and fast point lookups. The Reverse ETL pipeline must efficiently transfer data without overwhelming Postgres. This necessitates:
- Efficient data transfer mechanisms.
- Throttling strategies.
- Careful handling of
UPSERTandDELETEoperations on the target.
Technical Implementation: Step-by-step guide
This section details how to build a Reverse ETL pipeline from a Databricks Delta Lake table to Neon Postgres using PySpark and Spark Structured Streaming. We'll focus on an incremental sync strategy using Delta CDF. For the initial load, we'll use Spark JDBC to write data to Neon.
We will sync a sample customer_profiles table, which contains customer data that needs to be operationalized in Neon Postgres.
Prerequisites
- Databricks Workspace:
- Cluster running Databricks Runtime 13.3 LTS or above (for JDBC access and streaming capabilities).
Cluster Type
For the JDBC write, a "Classic" All-Purpose Cluster is required instead of Serverless compute due to limitations in Serverless environments regarding direct DML operations via generic JDBC. Additionally, mismatches between the client and server runtime particularly in Python versions can occur when using Serverless clusters, potentially leading to execution errors.
- Permissions:
- To read from the source Delta table(s).
- To create and run jobs/notebooks.
- Cluster running Databricks Runtime 13.3 LTS or above (for JDBC access and streaming capabilities).
- Neon Account & Postgres Database:
- A Neon project and database.
- Connection details (host, port, user, password, database name).
- Permissions: A dedicated Postgres role with
CONNECT,CREATE(on schema if needed),INSERT,UPDATE,DELETEpermissions on the target table(s).
Step 1: Prepare the Neon Postgres target table
Define the schema for your target table in Neon. Ensure you have primary keys for efficient updates/merges, and consider indexes on columns frequently used by your operational applications.
Example
Run the following CREATE EXTENSION statement in the Neon SQL Editor or from a client such as psql that is connected to your Neon database:
CREATE SCHEMA IF NOT EXISTS operational_data;
CREATE TABLE IF NOT EXISTS operational_data.customer_profiles (
customer_id VARCHAR(255) PRIMARY KEY,
full_name TEXT,
email VARCHAR(255) UNIQUE,
segment VARCHAR(100),
last_purchase_date TIMESTAMP WITH TIME ZONE,
total_spend NUMERIC(10, 2),
propensity_score FLOAT,
updated_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
_commit_timestamp TIMESTAMP -- For MERGE logic with Delta CDF
);Step 2: Prepare Source Databricks Delta Table & Enable CDF (optional)
If you don't already have a Delta table in Databricks, you can create one using the following SQL commands. This example shows how to create a customer_profiles_delta table with Change Data Feed (CDF) enabled, which helps track changes for incremental syncs. If you already have a Delta table, follow the Enable Change Data Feed (CDF) on Existing Delta Table section to enable CDF on your existing table.
Ensure you create your source Delta table in a Databricks catalog (e.g., hive_metastore) and enable Change Data Feed (CDF).
Example
Run the following SQL commands in a Databricks notebook cell to create the Delta table with CDF enabled:
USE CATALOG hive_metastore; -- Or your preferred catalog
CREATE SCHEMA IF NOT EXISTS operational_source_data;
USE SCHEMA operational_source_data;
-- Create the Delta table with Change Data Feed and Column Defaults enabled
CREATE TABLE IF NOT EXISTS hive_metastore.operational_source_data.customer_profiles_delta (
customer_id STRING NOT NULL COMMENT 'Unique identifier for the customer',
full_name STRING COMMENT 'Full name of the customer',
email STRING COMMENT 'Email address of the customer',
segment STRING COMMENT 'Customer segment (e.g., High Value, Churn Risk)',
last_purchase_date TIMESTAMP COMMENT 'Date of the last purchase',
total_spend DECIMAL(10, 2) COMMENT 'Total amount spent by the customer',
propensity_score DOUBLE COMMENT 'Score indicating likelihood of a future action (e.g., purchase, churn)',
is_active BOOLEAN COMMENT 'Flag indicating if the customer account is active',
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP() COMMENT 'Timestamp of when the record was created',
updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP() COMMENT 'Timestamp of when the record was last updated'
)
USING DELTA
TBLPROPERTIES (
'delta.enableChangeDataFeed' = 'true',
'delta.feature.allowColumnDefaults' = 'enabled',
'delta.autoOptimize.optimizeWrite' = 'true',
'delta.autoOptimize.autoCompact' = 'true'
)
COMMENT 'Delta table storing customer profile information for Reverse ETL to Neon.';
-- Insert some sample data
INSERT INTO hive_metastore.operational_source_data.customer_profiles_delta
(customer_id, full_name, email, segment, last_purchase_date, total_spend, propensity_score, is_active, created_at, updated_at)
VALUES
('cust_001', 'Alice Wonderland', 'alice.wonder@example.com', 'High Value', current_timestamp() - INTERVAL '10' DAYS, 250.75, 0.85, true, current_timestamp() - INTERVAL '90' DAYS, current_timestamp() - INTERVAL '10' DAYS),
('cust_002', 'Bob The Builder', 'bob.builder@example.com', 'New User', current_timestamp() - INTERVAL '2' DAYS, 50.20, 0.65, true, current_timestamp() - INTERVAL '5' DAYS, current_timestamp() - INTERVAL '2' DAYS),
('cust_003', 'Charlie Chaplin', 'charlie.chap@example.com', 'Churn Risk', current_timestamp() - INTERVAL '120' DAYS, 800.00, 0.23, true, current_timestamp() - INTERVAL '365' DAYS, current_timestamp() - INTERVAL '60' DAYS),
('cust_004', 'Diana Prince', 'diana.prince@example.com', 'Loyal Customer', current_timestamp() - INTERVAL '5' DAYS, 1250.50, 0.92, true, current_timestamp() - INTERVAL '180' DAYS, current_timestamp() - INTERVAL '5' DAYS),
('cust_005', 'Edward Scissorhands', 'ed.hands@example.com', 'Inactive', current_timestamp() - INTERVAL '400' DAYS, 150.00, 0.10, false, current_timestamp() - INTERVAL '500' DAYS, current_timestamp() - INTERVAL '300' DAYS),
('cust_006', 'Fiona Gallagher', 'fiona.g@example.com', 'High Value', current_timestamp() - INTERVAL '1' DAY, 320.00, 0.78, true, current_timestamp() - INTERVAL '30' DAYS, current_timestamp() - INTERVAL '1' DAY);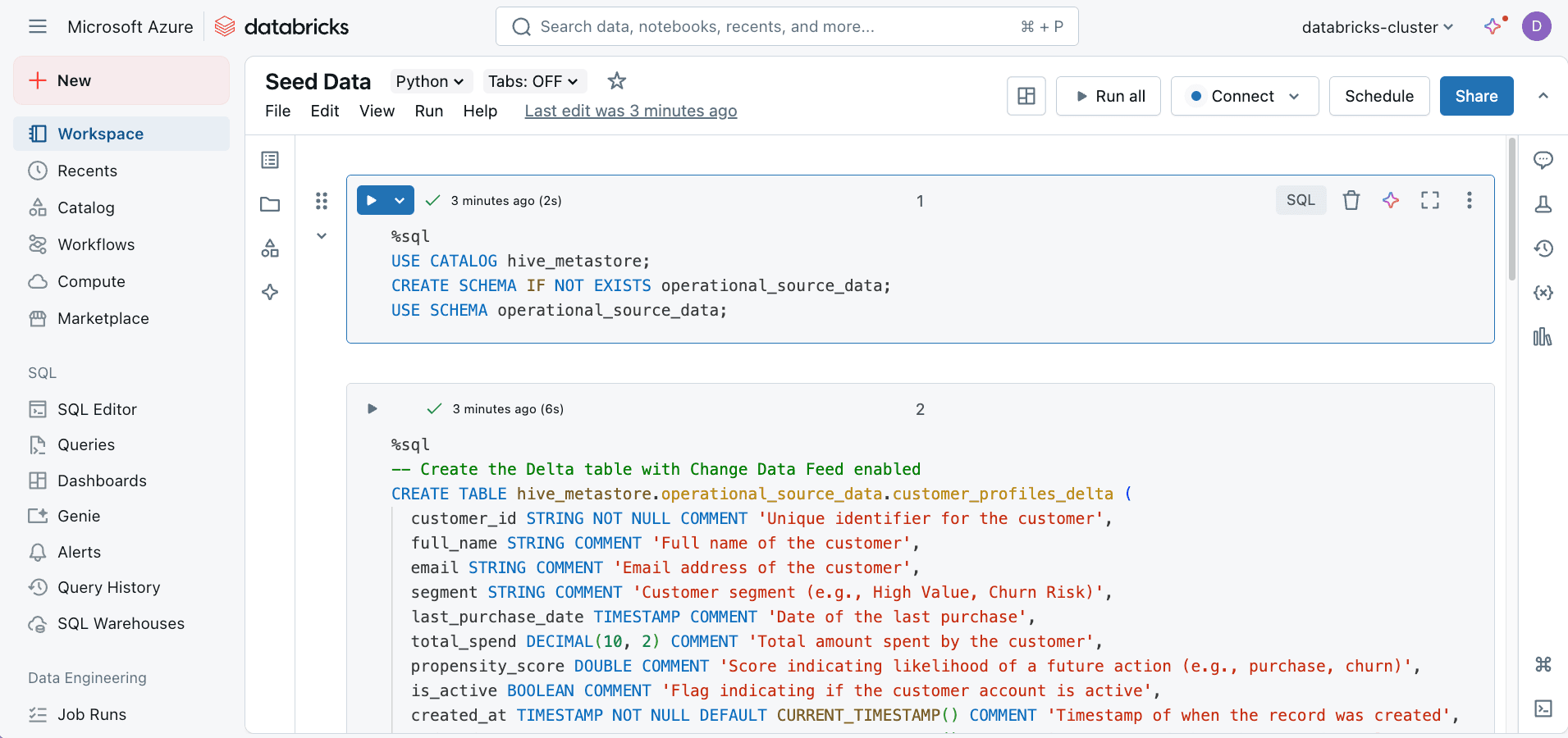
This dataset serves as a basic example to help you begin. In a production environment, your Delta table would typically contain a much larger and more intricate dataset.
Enable Change Data Feed (CDF) on existing Delta table
Run the following SQL command in a Databricks notebook cell to enable Change Data Feed (CDF) on an existing Delta table. This is necessary for incremental syncs to capture changes made to the table.
ALTER TABLE hive_metastore.operational_source_data.customer_profiles_delta
SET TBLPROPERTIES (delta.enableChangeDataFeed = true);Replace
hive_metastore.operational_source_data.customer_profiles_deltawith your actual Delta table name.
note
CDF only records changes made after it's enabled. Historical changes prior to enabling CDF won't be captured.
Step 3: Initial Data Load (One-Time)
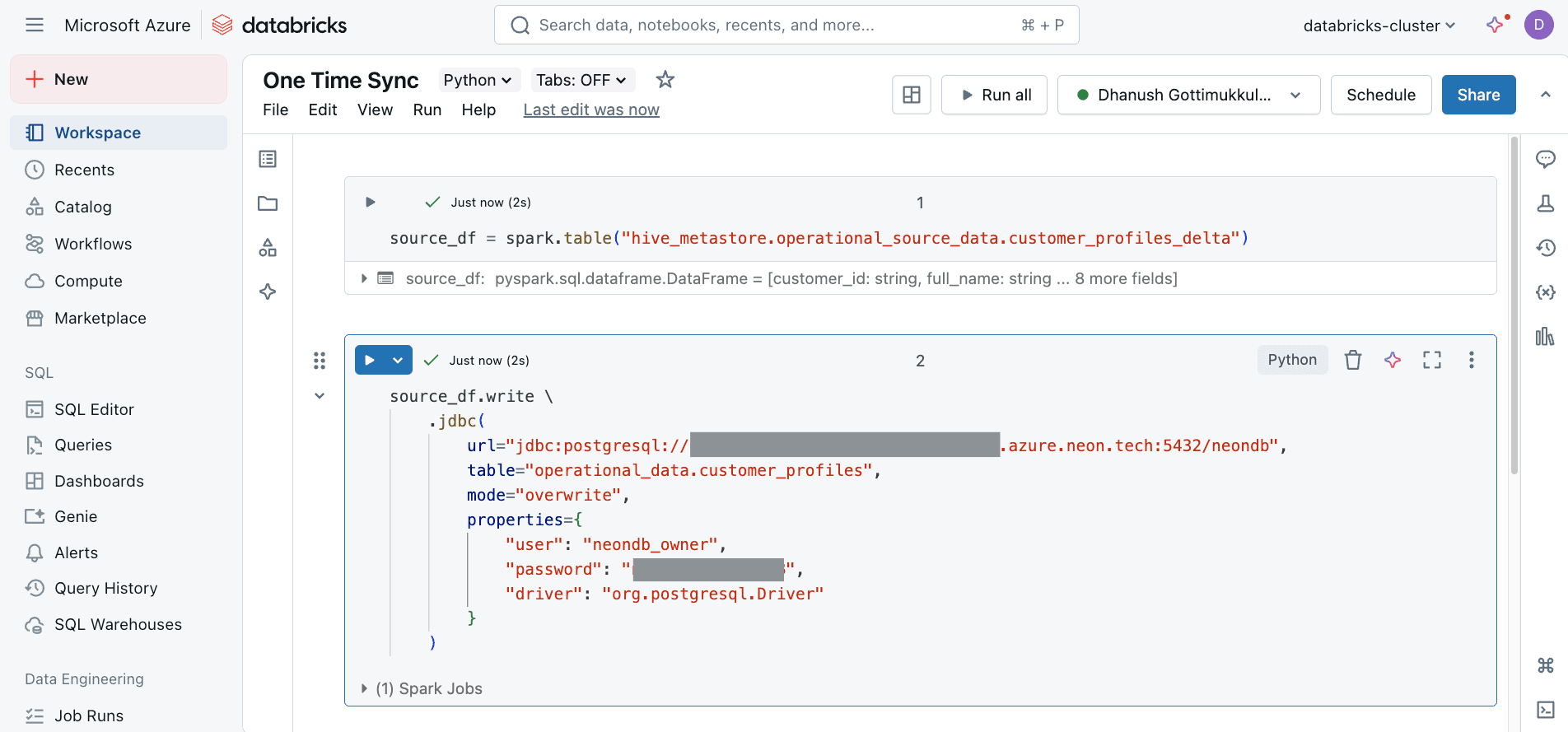
For the very first sync, perform an initial full load from the Delta table to the Neon target table. This uses Spark JDBC with mode="overwrite".
PySpark code for Initial Load
Run the following PySpark code in a Databricks notebook cell to perform the initial load from the Delta table to Neon Postgres. Make sure to replace the connection details and table names with your actual values.
source_df = spark.table("hive_metastore.operational_source_data.customer_profiles_delta")
source_df.write \
.jdbc(
url="jdbc:postgresql://<YOUR_NEON_HOST>:5432/<YOUR_NEON_DATABASE>",
table="operational_data.customer_profiles",
mode="overwrite",
properties={
"user": "<YOUR_NEON_USER>",
"password": "<YOUR_NEON_PASSWORD>",
"driver": "org.postgresql.Driver"
}
)!
note
The mode="overwrite" will replace the entire table in Neon. If the table must remain online or preserve existing data not covered by the source, consider a staging table and transactional swap strategy. For simplicity, this example uses overwrite.
Step 4: Implement Incremental Sync with Spark Structured Streaming & CDF
This PySpark code reads changes from the Delta table using CDF and applies them to Neon using a MERGE operation executed via psycopg2.
PySpark code for Incremental sync
Run the following PySpark code in a Databricks notebook cell to set up the incremental sync from the Delta table to Neon Postgres. This code uses Spark Structured Streaming to read changes from the Delta table and applies them to Neon Postgres using a MERGE operation.
from pyspark.sql import SparkSession, Window
from pyspark.sql.functions import col, row_number
import psycopg2
from psycopg2 import sql
neon_host = "<YOUR_NEON_HOST>"
neon_port = "5432"
neon_database = "<YOUR_NEON_DATABASE>"
neon_user = "<YOUR_NEON_USER>"
neon_password = "<YOUR_NEON_PASSWORD>"
target_schema = "operational_data"
target_table = "customer_profiles"
primary_key = "customer_id"
full_table_name = f"{target_schema}.{target_table}"
delta_table = "hive_metastore.operational_source_data.customer_profiles_delta"
checkpoint_path = "/mnt/reverse_etl_checkpoints/neon_customer_profiles_stream"
spark = SparkSession.builder.getOrCreate()
raw_stream = (
spark.readStream
.format("delta")
.option("readChangeData", "true")
.table(delta_table)
)
def write_to_neon(batch_df, batch_id):
print(f"Batch {batch_id}: received {batch_df.count()} records")
batch_df = batch_df.filter(col("_change_type") != "update_preimage")
win = Window.partitionBy(primary_key) \
.orderBy(col("_commit_version").desc(),
col("_commit_timestamp").desc())
deduped_df = (
batch_df
.withColumn("rn", row_number().over(win))
.filter(col("rn") == 1)
.drop("rn")
)
# Split upserts vs deletes
ups = deduped_df.filter(col("_change_type") != "delete")
dels = deduped_df.filter(col("_change_type") == "delete")
# Collect upsert rows
up_rows = ups.select(
primary_key, "full_name", "email", "segment",
"last_purchase_date", "total_spend", "propensity_score",
"_commit_timestamp", "created_at"
).collect()
# Perform MERGE on Neon for upserts
if up_rows:
cols = [
primary_key, "full_name", "email", "segment",
"last_purchase_date", "total_spend", "propensity_score",
"_commit_timestamp", "created_at"
]
vals_sql = ",".join([
"(" + ",".join(["%s"] * len(cols)) + ")"
for _ in up_rows
])
params = [getattr(r, c) for r in up_rows for c in cols]
merge_sql = f"""
MERGE INTO {full_table_name} AS target
USING ( VALUES
{vals_sql}
) AS source({','.join(cols)})
ON target.{primary_key} = source.{primary_key}
WHEN NOT MATCHED THEN
INSERT ({','.join(cols)}, updated_at)
VALUES ({','.join([f"source.{c}" for c in cols])}, NOW())
WHEN MATCHED AND (
target._commit_timestamp IS NULL
OR source._commit_timestamp >= target._commit_timestamp
) THEN
UPDATE SET
full_name = source.full_name,
email = source.email,
segment = source.segment,
last_purchase_date= source.last_purchase_date,
total_spend = source.total_spend,
propensity_score = source.propensity_score,
_commit_timestamp = source._commit_timestamp,
updated_at = NOW()
;
"""
conn = psycopg2.connect(
host=neon_host, port=neon_port,
dbname=neon_database,
user=neon_user, password=neon_password
)
try:
cur = conn.cursor()
cur.execute(merge_sql, params)
conn.commit()
print(f"Upserted {len(up_rows)} rows.")
except Exception as e:
conn.rollback()
print("Error during MERGE:", e)
raise
finally:
cur.close()
conn.close()
# Process deletes
del_ids = [r[primary_key] for r in dels.select(primary_key).collect()]
if del_ids:
conn = psycopg2.connect(
host=neon_host, port=neon_port,
dbname=neon_database,
user=neon_user, password=neon_password
)
try:
del_sql = sql.SQL(
"DELETE FROM {} WHERE {} = ANY(%s)"
).format(
sql.Identifier(target_schema, target_table),
sql.Identifier(primary_key)
)
cur = conn.cursor()
cur.execute(del_sql, (del_ids,))
conn.commit()
print(f"Deleted {len(del_ids)} rows.")
except Exception as e:
conn.rollback()
print("Error during DELETE:", e)
raise
finally:
cur.close()
conn.close()
(
raw_stream.writeStream
.foreachBatch(write_to_neon)
.option("checkpointLocation", checkpoint_path)
.trigger(availableNow=True)
.start()
)This PySpark script sets up a streaming Reverse ETL pipeline to synchronize incremental data changes from a Databricks Delta table to a Neon Postgres database.
Here's a breakdown of what it does:
-
Configuration & Setup: It defines connection parameters and specifies the source Delta table and target Neon Postgres table.
-
Reading Incremental changes from Delta Lake:
- It configures a Spark Structured Stream to read from the specified Delta table (
delta_table). - Crucially,
option("readChangeData", "true")enables it to consume the Change Data Feed (CDF) from the Delta table. This means it only processes rows that have been inserted, updated, or deleted since the stream last processed data.
- It configures a Spark Structured Stream to read from the specified Delta table (
-
Processing each batch of changes (
write_to_neonfunction):- This function is executed for each micro-batch of change data received from the Delta stream.
- Deduplication: It first filters out
update_preimagerecords (which represent the state before an update and are usually not needed for direct synchronization). Then, it uses a Spark window function to deduplicate changes within the batch. For any given record (identified byprimary_key), it keeps only the latest change based on_commit_versionand_commit_timestampfrom the Delta CDF. - Separating operations: The deduplicated changes are then split into two DataFrames:
upsfor records to be inserted or updated (upserted), anddelsfor records to be deleted. - Handling Upserts:
- It collects the rows marked for upsert into a Python list.
- It dynamically constructs a Postgres
MERGEstatement. This statement is designed to:INSERTnew rows if they don't exist in the target Neon table (based on theprimary_key).UPDATEexisting rows if the incoming change is newer (checked using the_commit_timestampfrom Delta if present in the target, or simply if a match is found).
- It executes the
MERGEstatement with the collected data, committing the transaction if successful or rolling back on error.
- Handling Deletes:
- It collects the primary key values of rows marked for deletion.
- It executes a
DELETEstatement in Neon to remove these records from the target table, again using transactions.
-
Writing the Stream to Neon:
- The script configures the output of the
raw_stream. foreachBatch(write_to_neon): Specifies that the customwrite_to_neonfunction should be applied to each micro-batch.option("checkpointLocation", checkpoint_path): This is vital for fault tolerance and ensuring exactly-once processing semantics (within Spark's capabilities). The stream remembers where it left off.trigger(availableNow=True): This makes the stream behave like a batch job. It processes all available data that has arrived since the last run and then stops. This is suitable for scheduled pipeline runs..start(): Initiates the streaming query.
- The script configures the output of the
In essence, the code continuously (or on a scheduled basis due to availableNow=True) checks for new changes in a Delta table, processes these changes to find the latest state for each record, and then applies these inserts, updates, or deletes to a target table in Neon Postgres, keeping the two synchronized.
Verification:
After setting up and running the initial load and the incremental sync job:
- Make some changes (inserts, updates, deletes) to your source
customer_profiles_deltatable in Databricks. - Run the incremental sync Databricks job.
- Query your
operational_data.customer_profilestable in Neon Postgres to verify that the changes have been replicated.
Step 5: Orchestration and Scheduling
To automate the Reverse ETL process, you can utilize Databricks Jobs or schedule the notebook to run at regular intervals. For detailed information on scheduling, please refer to Databricks: Create and manage scheduled notebook jobs.
Conclusion
Implementing Reverse ETL from Databricks Delta Lake to Neon Postgres operationalizes your valuable analytical insights, empowering real-time applications, AI agents, and frontline business teams. By leveraging Delta Lake's Change Data Feed and Spark Structured Streaming, you can build efficient, incremental pipelines that keep your Neon Postgres database synchronized with your analytical truth.
References
- Databricks Delta Lake Change Data Feed
- Spark Structured Streaming + Delta Lake
- Automating jobs with schedules and triggers
- Enabling Operational Analytics on the Databricks Lakehouse Platform With Census Reverse ETL
- Using Hightouch for Reverse ETL With Databricks
- Neon Documentation
- Building a Reverse ETL Pipeline: Upserting Delta Lake Data into Postgres with Structured Streaming
Need help?
Join our Discord Server to ask questions or see what others are doing with Neon. Users on paid plans can open a support ticket from the console. For more details, see Getting Support.